起因
我在互联网上留下痕迹,比写代码还早。
大学时代就开始折腾博客、刷微博、玩人人网,那时候还没入行做程序员,纯粹就是一个爱在网上表达的人。后面这十几年,从最开始的切图仔,到后来资深前端开发,再到现在的 AI 驱动的全栈开发,有了技术加持,输出变得更加系统化。到今天,
除了博客,还有 

这些内容散落在互联网的各个角落,涵盖了技术、摄影、旅行、跑步、数码产品、生活方式等话题。如果有人想快速了解「罗磊是谁」,他需要翻好几个平台、读上几十篇文章,才能拼凑出一个大概的印象。
2024 年至今,我全身心投入独立开发,拥抱 AI-first 的 Vibe Coding 工作流。在这个过程中,一个想法越来越清晰:
在生成式 AI 时代,你的内容一定会被 AI 读取。但 AI 是否能完整地理解你,取决于你是否主动构建自己的知识结构。
被动被爬虫抓取,和主动建立语义索引,是两回事。让 AI 理解你,本质是在拿回对自己内容的解释权。
于是我决定在博客上做两件事:让多个 AI 模型以第三方视角写出「AI 眼中的罗磊」,以及基于我多年的多平台内容构建 RAG 知识库,做一个可以直接聊天的「AI 罗磊」。
AI 眼中的罗磊
打开
这个页面不是我自己写的自我介绍,而是由 6 个不同的 AI 模型(GPT-5.2、Gemini 3、Qwen 3.5 Plus、Kimi K2.5、豆包 Seed 2.0、GLM 5.0)分别阅读我的博客文章、X 动态和 GitHub 履历后,各自生成的第三方视角作者画像。
同一份数据,不同模型,像 6 个旁观者各自写出对同一个人的理解。
数据从哪来
这次 AI 分身主要围绕三类数据进行分析:
- 博客文章:300+ 篇 Markdown 文件,每篇都经过 AI 预处理生成结构化摘要(含一句话摘要、详细摘要、3-6 条关键要点、SEO 关键词)
- X/Twitter 动态:通过官方 API 抓取,按互动量排序取最有代表性的内容
- GitHub 履历:项目信息、工作经历、技术栈
说实话,这只是我在网上留下的数据的一小部分。我在 YouTube 和 B 站上有大量视频内容,十几年前的微博和人人网上也有不少早期的文字记录。但这些平台的数据抓取非常麻烦——视频需要先转文字再分析,国内社交平台的 API 要么不开放、要么限制很多,和 Twitter 的官方 API 体验完全不在一个级别。
即使是 Twitter API,成本也不低。所以我做了本地缓存策略,抓取一次后存到 JSON 文件里,避免重复调用。
11 万字的上下文挑战
这三类数据汇总后,光是 Context JSON 就有大概 11 万字。把这么大的数据量一次性丢给 AI 分析,直接暴露了当前大模型的能力边界。
实测下来,6 个模型中只有 Qwen 和 Gemini 3 能稳定处理这个量级的上下文。其他几家要么超时、要么输出质量严重下降,甚至直接报错。最后我做了一轮 AI 预处理——先用模型对每篇文章生成摘要和关键要点,再把压缩后的结构化数据丢给各个模型生成画像,才解决了这个问题。
这是当前 AI 能力的一个现实限制。但可以想象的是,随着大模型的上下文窗口持续扩大,未来普通用户也能轻松处理几十万字的长文分析。到那时候,做这种个人知识系统的门槛会低很多。
多模型生成
6 个模型使用统一的 System Prompt,要求以第三方视角生成结构化 JSON 报告,包括身份标签、能力维度、做事风格、代表作品等。Prompt 中有严格约束:语气客观克制,结论必须有数据支撑,不能编造,不能夸大。
前端支持在不同模型视角之间切换,每个画像底部标注了生成模型、时间和数据来源,保持透明。
为什么让多个 AI 来写?一个 AI 的输出可能有偏差,但当多个不同架构、不同训练数据的模型都指向类似的结论时,可信度就高了不少。同时不同模型的表达差异,本身就挺有意思——有的模型更关注技术能力,有的更关注内容创作,有的会注意到生活方式这条线。

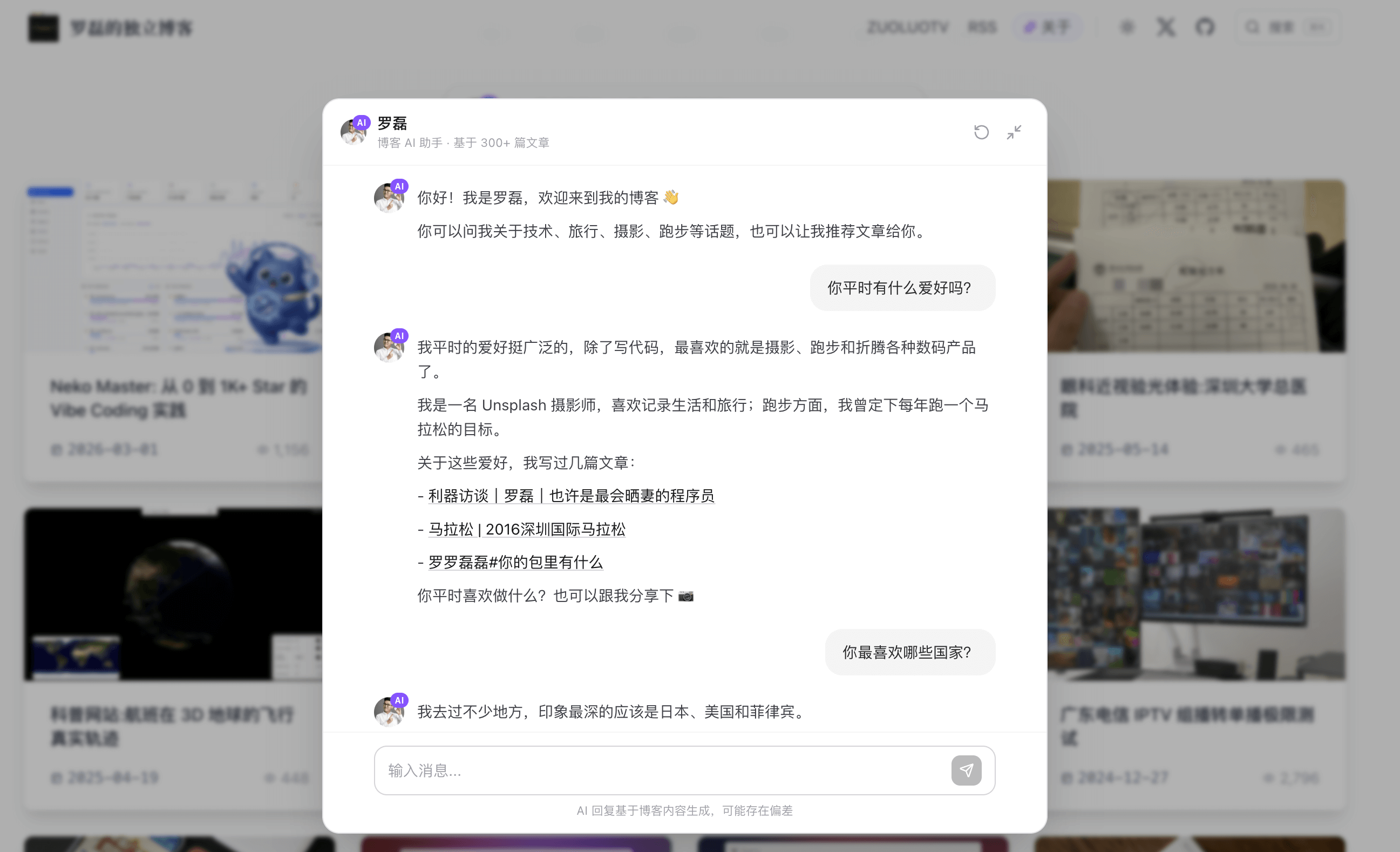
在博客里和 AI 版的我聊天
/about 页面解决的是「快速了解我」的问题。但如果读者想深入聊一个具体话题——比如「你用什么设备拍照」「你跑过哪些马拉松」「推荐几篇关于 Homelab 的文章」——一个静态画像页面就不够了。
于是我做了第二个功能:直接在博客和 AI 版本的我聊天。
技术栈
- 框架:
Vinext(基于 Vite 的 Next.js 重实现,部署在 Cloudflare Workers)
- AI SDK: Vercel 的
AI SDK(
ai+@ai-sdk/react+@ai-sdk/openai-compatible) - LLM: 通过 OpenAI Compatible API 接入,支持切换任意模型(通义千问、DeepSeek、Gemini、OpenAI 等)
- 搜索/RAG: 自建的
@luoleiorg/search-core包,基于关键词匹配 + 权重评分 + 意图重排 - 安全: IP 级速率限制(防止滥用)
- 监控: Telegram Bot 实时通知,完整追踪 Token 用量和阶段耗时
工作流程
当读者在聊天框输入一条消息,系统的处理链路如下:
1. 搜索上下文复用判断
系统会缓存每轮对话的搜索上下文(10 分钟有效期)。如果是追问(比如先问「你跑过马拉松吗」,再问「成绩怎么样」),会通过以下步骤判断是否复用:
- 追问检测:基于消息长度(≤48 字符)、标点符号、词数等启发式规则,快速识别可能的追问
- 意图判定:调用轻量级 AI(1.5 秒超时,8 token 输出上限)判断新问题与上轮是否属于同一检索意图
- 缓存复用:如果判定为同一意图,直接复用上次的检索结果,避免重复搜索
2. 并行搜索与关键词提取
如果不复用缓存,系统会同时启动两个并行任务:
本地搜索(即时):基于 @luoleiorg/search-core 倒排索引,使用 Intl.Segmenter 进行中文分词,并做 CJK 字符拼接修复(比如把「马拉」+「松」识别为「马拉松」)。搜索算法使用加权评分:
- 标题匹配 +6 分
- 摘要匹配 +4 分
- 关键要点匹配 +3 分
- 正文匹配 +2 分
- 一年内文章 +1 分
深度内容提取:对于匹配度最高的文章(分数 ≥8 且显著领先第二名),会额外提取前 1500 字符的完整内容,让 AI 能回答更细节的问题。
AI 关键词提取(异步并行):如果是多轮对话且本地关键词不足 3 个,会调用 AI 从对话上下文中提取更精准的搜索关键词(3.5 秒超时,48 token 输出上限)。提取后会过滤 70+ 个中文停用词。如果 AI 提取的关键词与本地分词结果不同,会用新关键词再次搜索。
最终返回 6 篇最相关的博客文章 + 6 条最相关的 X 动态。
3. 意图重排
系统定义了 5 类意图分类:
- AI/RAG:ai、rag、embedding、agent、llm、prompt、数字分身、向量、大模型
- DevOps/Homelab:docker、k8s、nginx、cloudflare、openwrt、homelab、路由
- 前端/全栈:nextjs、react、typescript、seo、vinext、前端、全栈
- 摄影/旅行:摄影、旅行、东京、香港、京都、unsplash、马拉松
- 生活方式:生活、消费、眼镜、医院、体验、投资、健康
根据用户查询内容识别意图后,对检索到的文章进行重排,按意图相关度评分:
- 标题命中 +3 分
- 分类命中 +2 分
- 摘要命中 +2 分
- 关键要点命中 +1 分
- 一年内文章 +1 分
这样可以优先展示最相关领域的内容。
4. 分层 Prompt 构建
System Prompt 分为三层:
- 核心身份:AI 人设定义、语言风格、交互原则
- 核心规则(反幻觉协议):来源限制、数字协议、履历协议、链接协议
- 运行时上下文:作者简介 + 相关文章/动态列表 + 用户查询
这种分层设计让提示词维护更清晰,也方便调整规则而不影响其他部分。
5. 流式生成与修复
AI 以 Streaming 方式逐字输出(temperature=0.3,max_tokens=2000)。如果检测到响应截断(以悬停标点结尾、Markdown 不平衡、句子不完整等),会触发一次轻量级修复调用(2.5 秒超时,80 token 上限),只补全最后一句,然后无缝拼接。
6. 全链路追踪
每轮对话结束后,Telegram Bot 会发送详细通知,包括:
- Token 用量细分:输入 token、输出 token、推理 token、缓存 token(分阶段统计:关键词提取、主对话、响应修复)
- 各阶段耗时:总耗时、关键词提取耗时、检索耗时(标注是否命中缓存复用)、Prompt 构建耗时、响应修复耗时
- 引用内容:文章标题列表、推文标题列表

反幻觉:系统工程
做 AI 数字分身最大的挑战不是「让它说话」,而是「让它不乱说」。
大语言模型天生倾向于「编出一个看起来合理的答案」。如果有人问「你有没有去过冰岛」,一个没有约束的模型可能会非常自信地说「有啊,我 2022 年去过」,哪怕我压根没去过。
所以在系统提示词中,我设置了最高优先级的反幻觉规则:
- 来源限制协议——只能使用本次 Prompt 中的可见信息
- 数字协议——任何具体数字(金额、日期、成绩)必须在文本中出现,否则简洁承认没有记录,且同一轮对话中不得重复相同的表述
- 履历协议——工作经历只以「关于你」为准,没有记录时使用模板「这个细节我没在博客里记录」
- 链接协议——只允许引用提供的完整 URL,必须使用 Markdown 格式
[文字](URL),严禁裸输出 URL
这些规则配合 RAG 检索,让 AI 的回答始终有据可查。搜不到就坦诚说没有,比编一个像模像样的假答案好一百倍。
前端细节
聊天界面的一些设计:移动端全屏、桌面端居中弹窗;键盘 Enter 全局唤起;消息气泡区分用户和 AI,AI 头像带「AI」标识;3 秒发送冷却防误触;预设引导语轮播帮助用户开启话题。
当 AI 回复中引用 X/Twitter 动态时,前端会自动渲染成带有作者头像、互动数据的卡片,点击可展开查看完整推文。
每一次对话都会通过 Telegram Bot 通知到我手机,我能实时看到有多少人在和「AI 罗磊」聊天,聊了什么话题,引用了哪些文章,以及系统在各阶段花了多少时间、消耗了多少 Token。
它是我,又不是我
和自己的 AI 分身聊天,感觉挺奇妙的。
它知道我 2014 年跑了上海马拉松,知道我用 Cloudflare Workers 部署项目,知道我在 2016 年写过一篇关于信息自由的文章。它能推荐我写过的文章,能聊我的技术栈,能说出我用什么相机。
但它不是我。
这个 AI 版的罗磊,是基于我公开发布的内容训练出来的。公开内容天然有筛选和表达倾向——我在博客里写的是我愿意分享的部分,X 上发的是我想表达的观点,GitHub 上展示的是我选择开源的项目。那些没写出来的犹豫、没发出去的想法、生活中琐碎但真实的部分,AI 一无所知。
所以这个数字分身呈现出来的形象,一定和我真人的性格有差异。它可能显得比我更自信、更系统化、更「有条理」,因为发布出来的内容本身就经过了思考和整理。真实的我,可能比它犹豫得多,也随意得多。
这种偏差其实挺值得思考的。我们每个人在互联网上呈现的形象,本来就是真实自我的一个投影。AI 读取的是投影,重建的也是投影。它理解的是那个「在线的罗磊」,而不是完整的罗磊。
养成系的 AI 分身
做这个东西有点像养成游戏。
目前它的知识库还只覆盖了博客、推文和 GitHub。接下来我打算把 YouTube 和 B 站上的所有视频都处理一遍——先转成文字,再做分析和索引,然后继续「投喂」给这个系统。数据越多,它对我的理解就越完整。
不过说实话,我也有一些隐忧。
目前整个系统的 AI 能力依赖于大厂的 API 服务——通义千问、OpenAI、Gemini,数据传输到他们的服务器上处理。因为我喂给它的都是公开数据,所以隐私问题暂时不太担心。但如果未来想把更私密的内容也纳入进来,就需要认真考虑数据安全了。
另一个风险是依赖性。当你把自己的知识体系建立在第三方服务之上,一旦 API 涨价、服务下线、或者政策变化,整个系统就可能受到影响。这也是为什么我选择了 OpenAI Compatible 的接口标准——至少在模型层可以随时切换,不被单一供应商锁定。
最后
回到最开始的那个观点:在这个时代,主动构建自己的知识结构,远比被动等待 AI 来理解你更重要。
我的博客、推文、视频、代码,如果只是散落在互联网各处,它们就只是搜索引擎里的一条条索引。但当我主动把它们结构化、建立语义关联之后,它们变成了一个可以对话的知识体。
可以想象的是,随着 AI 大模型能力的持续增强,以后的上下文窗口会越来越大,多模态处理会越来越成熟。到那时候,做一个自己的 AI 分身,可能就像今天搭建一个博客一样简单。
这也许就是个人内容创作者在 AI 时代的一种可能性:不只是生产内容,而是构建自己的知识系统。让 AI 成为你的延伸,而不只是替代。
相关链接
- AI 视角下的罗磊:
- AI 数字分身聊天:
- 博客源码:
- AI SDK:
- Vinext: